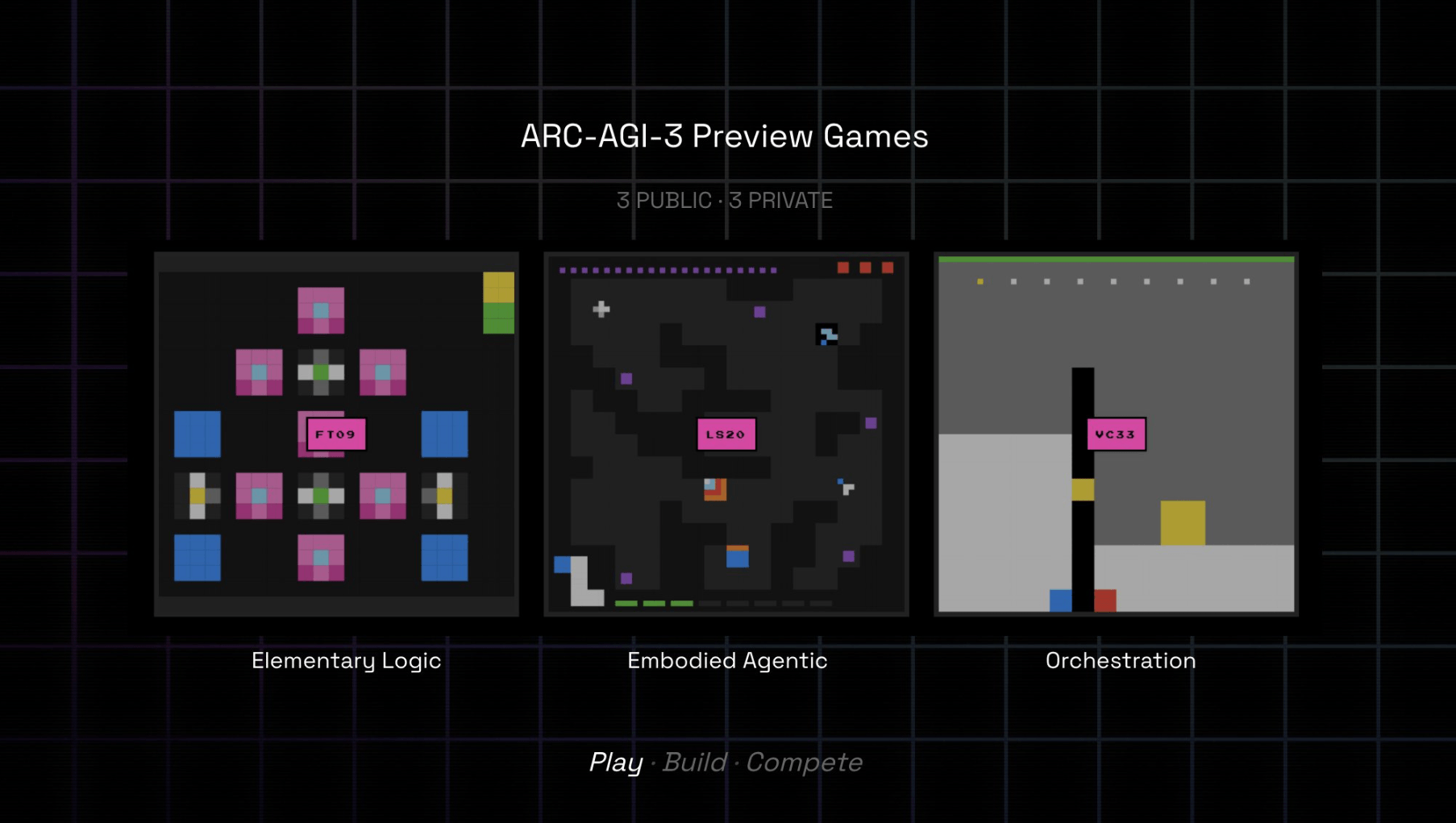
New ARC-AGI-3 benchmark shows that humans still outperform LLMs at pretty basic thinking
ARC-AGI-3 aims to test how well AI systems can handle brand new problems. While people breeze through the challenges, the latest AI models still come up short.
The article New ARC-AGI-3 benchmark shows that humans still outperform LLMs at pretty basic thinking appeared first on THE DECODER.
Rating
Innovation
Pricing
Technology
Usability
We have discovered similar tools to what you are looking for. Check out our suggestions for similar AI tools.
venturebeat
venturebeat
venturebeat


venturebeat